Joining the dots for modern data science workflows
State of the art workflows not just for Computer Scientists
July, 2024
The workflow’s components - a Pyramid scheme

Component 1: the physical computer

- this can be many things
- your local laptop (don’t forget it on the bus 🚌)
- your office computer 🏢
- your lab-groups’ computer 🔬
- a Virtual Machine 📡
- 3 sentences about VMs
- we will use one in our project
- a cloud resource ☁️ (might be obfuscated, might be a server similar to a VM)
Component 2: the operating system

- Selected tools are maximised for
- being Operating System (OS) agnostic
- they should work on many systems
- some (!) trouble-shotting in aforementioned Drop-in Clinic or over Slack
Note
because of the way we interact with the core-coding task, we won’t see too much of the OS
Component 3: the programming language

- we will use Python 🐍
- Python vs. R vs. C vs. Rust vs. JS, … is out of scope
- Try one of these sessions If your goal is…
(all these ResBaz session are running concurrently on Wed. 1-5pm)
Component 4: Libraries

- We will talk more about packages/libraries in due course
- For now: Python has a vast amount of libraries
- we will use GeoPandas among others
- efficiently handling these might appear daunting
- but we will show you some tricks
- many others have done this before!
Component 5: the programming environment
 We have two main appraoches
We have two main appraoches

command-line interface (aka CLI/terminal/console/shell/BaSH/ZSH/Fish/…):
- automatically, for ex. every night at 11pm (cron-job)
- chain one scripts output as an input to another script (build a pipeline)

Jupyter Notbooks, etc.:
- develop your code
- explore your data
- get interactivity
- run bits and pieces in Isolation
Pyramid revisited: Research Reproducibility perspective
- What can we do to maximise Reproducibility?1
- Handling data with code has some advantages over GUI spreadsheet tools where you accidentally click on a cell and move it, etc.

VSC and GitHub
- VSC we can either use the lefthand side-panel for git (once extension is installed), or we can use the CLI below to do
git status,git diff,git commit -am "present-tense active what I did"1,git push
- GitHub can also provide us with
- GitHub Actions (throw-away-VMs running on MSAzure)
- Some basic Project Management via Issues
- Collaboration (allow other to work on your code)
- private and public repos
- there are academic discounts, …

Revisit the Pyramid
(input data properly stored ✅ we use an IDE (VSC) ✅ use package management ✅)
- Containers (Think of a mini-VM) Docker, Kubernetes
- Pick/reference an OS (say Ubuntu 22.4) + a Python version (say 3.11.6), etc.
- your local/VM machine runs
KernelandVSC - put the result on DockerHub
- BinderHub: you can package a remote Git repository into an interactive Jupyter notebook for displaying code and output
- Research Object (RO) Crate: an approach to package research data and its metadata human and machine readable
- the Workflow aspect can ingest or generate an RO-Crate that describes the complete processes, authorship, and requirements of a computational workflow

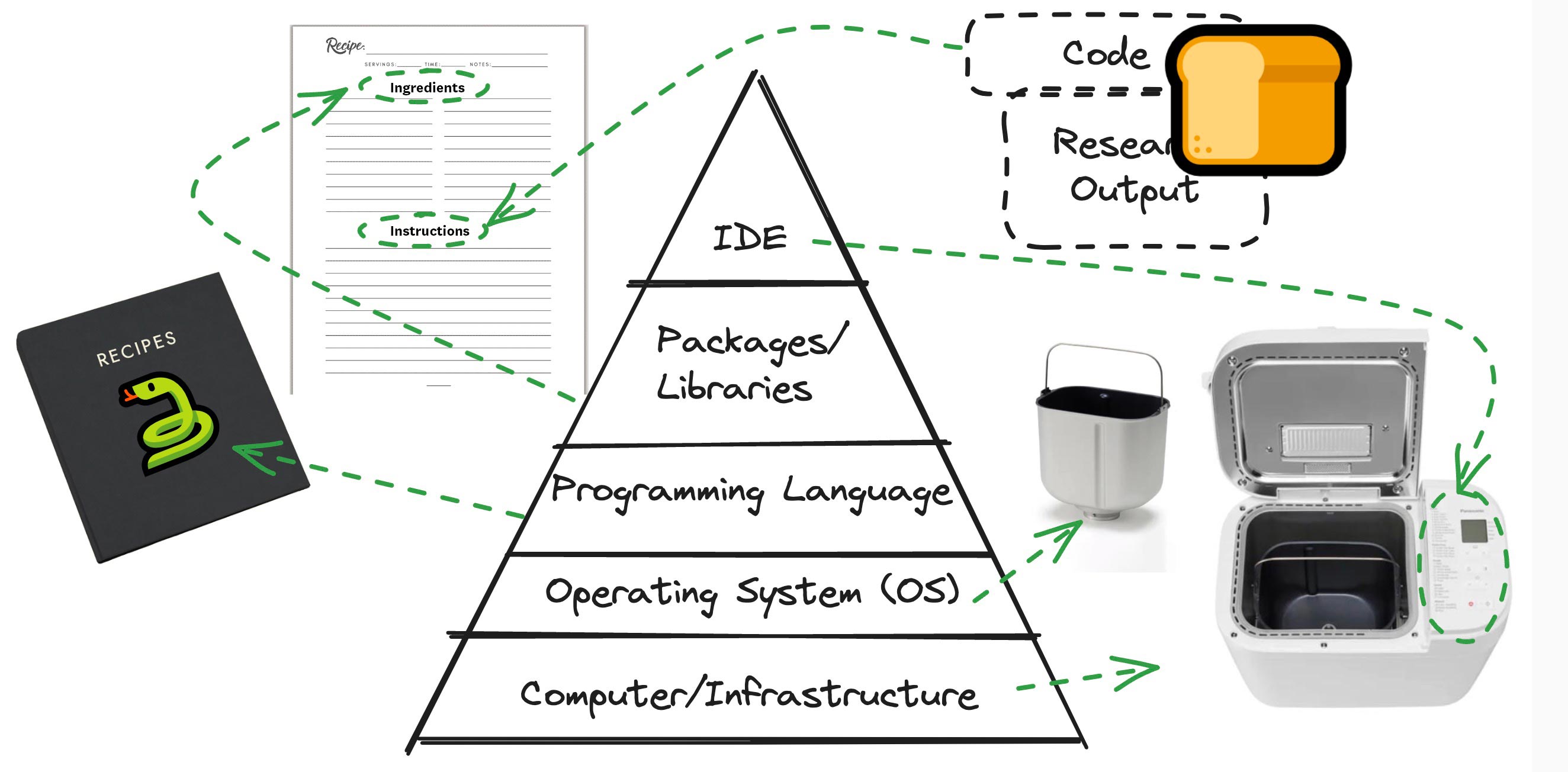
Let’s iterate: The pyramid adapted to baking bread 🍞
Questions
- please see the explanation above
- the likelihood of me being able to answer your question now is quite slim
- a lot of content in 1h
- Come to HackyHour or the Drop-in Clinic
Joining the dots for modern data science workflows